Can Polymarket Make You a Better Equity Analyst?
Two real company case studies on where prediction markets genuinely improve equity models (and where they still need human judgment)

Using AI has opened up a new class of inputs for company modelling.
One of the most interesting is probability markets: Kalshi, Polymarket, and similar platforms that turn disputed real-world outcomes into live prices. We recently integrated Polymarket into Primer, and the results have been much more interesting than I expected.
The appeal is obvious. As an analyst or portfolio manager, there are plenty of situations where you do not want to pretend you have some uniquely precise probability in your head for a policy decision, a legal outcome, or a regulatory event. A live market price gives you a starting point.
But that is also where people go wrong.
The point is not that probability markets let you outsource judgment. The point is that they can give you a live external probability anchor, which you then have to translate into company economics properly.
That distinction matters.
Used lazily, these markets are just a shiny new shortcut. Used properly, they can become a genuinely useful modelling input.
Two AI test cases made that very clear.
Case Study 1 - Tariff Impact
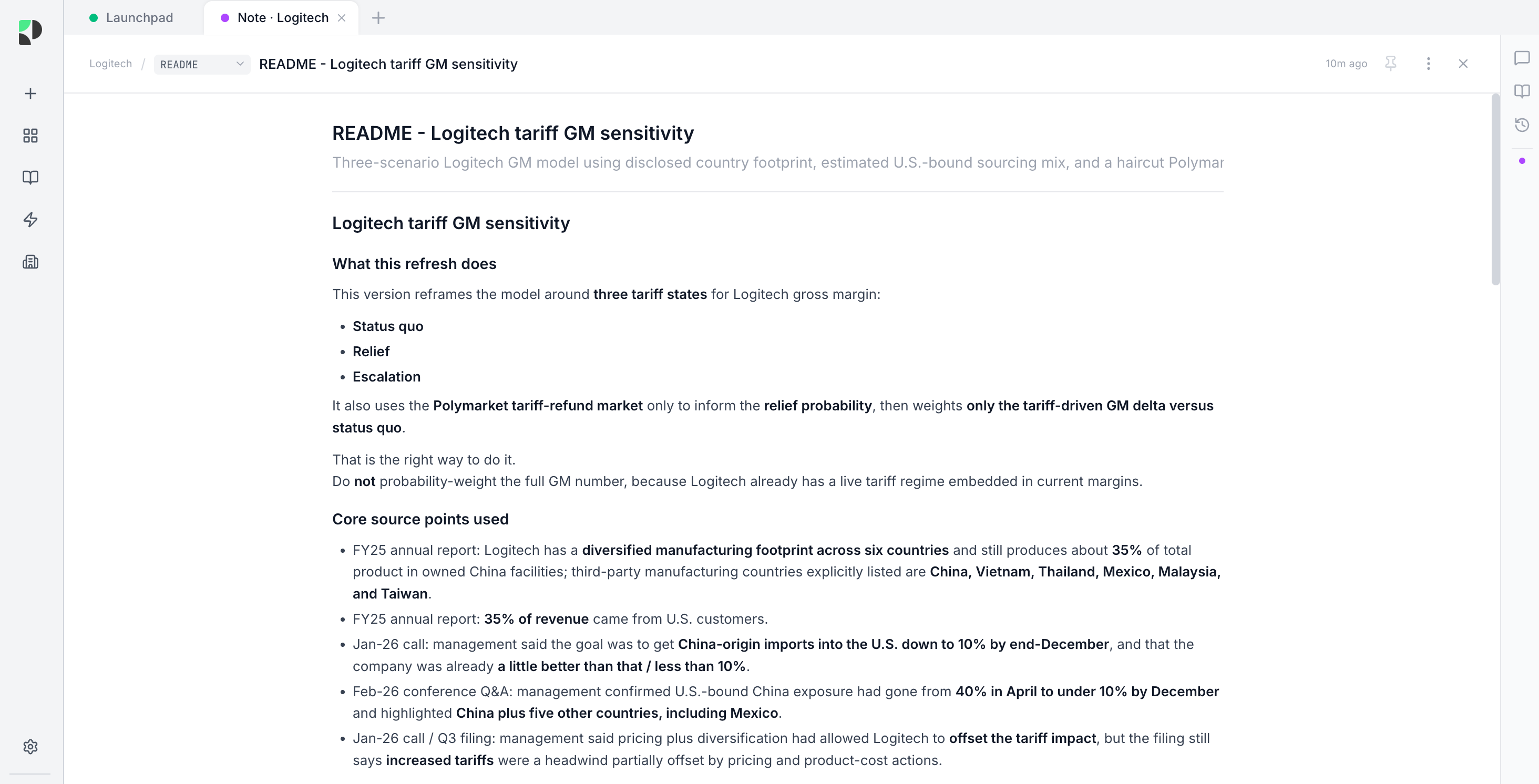
The first case study was Logitech, a company I covered previously, and one where I had already spent a lot of time thinking through tariff outcomes the hard way.
The original exercise was exactly the kind of painstaking work analysts know well: map Logitech’s supply chain, work out which parts of the manufacturing footprint really matter for the U.S. P&L, think through mitigation, and then translate all of that into potential gross margin outcomes under different tariff paths.
The prompt was:
Build a scenario model for Logitech gross margin driven by potential tariff outcomes. Map their supply base by country and use the Polymarket tariff-refund probability. Quantify GM impact in bps under status quo, relief, and escalation scenarios, and calculate a probability-weighted GM by weighting only the tariff-driven delta, not the full GM. Output the assumptions, scenario table, and your recommended effective probability.
The Output



What was actually good here
What stood out was not just the arithmetic. It was the parts that looked like a real analyst using judgment rather than just filling in a spreadsheet.
1) It mapped the problem to the economically relevant exposure
A weak process would stop at: Logitech manufactures in Asia, tariffs are bad.
This one narrowed the problem to what actually mattered:
U.S.-bound exposure, not total global production
China share of U.S.-bound supply, not just total China manufacturing
U.S. revenue / COGS exposure, because that is the route through which tariffs actually transmit into group margin
That is much closer to how a good analyst thinks.
The right question is never just what is exposed? It is what is exposed, through which channel, and how much can it really move the group P&L?
2) It used management commentary properly
The key insight it picked up was that Logitech had already shifted from:
roughly 40% China-origin U.S.-bound supply
to less than 10% by December
That changes the whole debate.
Without that, you get the lazy conclusion: tariff relief equals large upside.
With it, you get the more intelligent framing:
upside from tariff relief is still real, but now more limited
the more important downside is a broader re-escalation across the non-China footprint
That is a much better answer, because it reflects what the company has actually done rather than relying on an outdated narrative.
3) It did not use Polymarket mechanically
This was probably the most analyst-like part of the whole exercise.
A weaker version would have said:
Polymarket says 51%
therefore use 51%
Instead, it recognised that:
the Polymarket market resolved on a legal refund event
Logitech gross margin depends on economic relief
those are not necessarily the same thing
so the raw market probability needed a haircut
That is exactly the kind of translation work a human analyst has to do when using market-implied signals inside a company model.
4) It weighted the delta, not the full gross margin
This was subtle, but important.
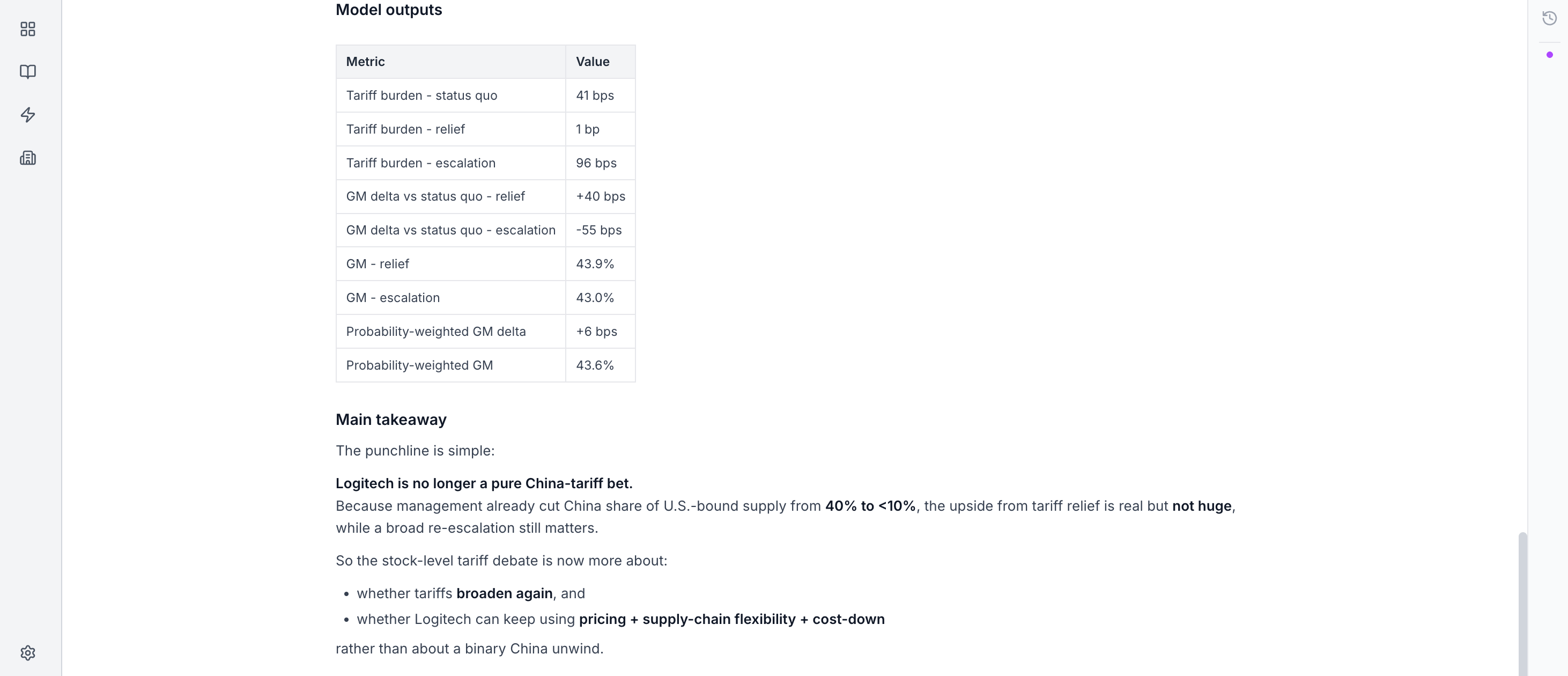
The model recognised that Logitech already has a live tariff regime embedded in current margins. So the correct framework was:
start from status quo gross margin
then probability-weight the incremental upside or downside from relief or escalation
That is proper modelling logic.
A less thoughtful model would have probability-weighted the entire gross margin stack and quietly double-counted the existing tariff environment.
5) It built a sensible scenario tree instead of forcing binary thinking
Rather than reducing the world to:
relief
no relief
it used:
status quo
relief
escalation
That is much more realistic.
In policy and legal situations, the base case is often not a clean win or loss. It is muddle-through. That is how analysts actually think about these situations: what stays the same, what improves, and what gets worse?
6) It made a real recommendation
It did not hide behind “it depends.”
It came out with a view:
raw refund probability = 51%
effective Logitech GM probability = 35%
and most of the residual probability belongs in status quo, not escalation
That is useful.
Real research requires taking the final step from evidence to an opinion.
7) It recognised that the thesis itself had changed
This may have been the best conceptual point.
The exercise concluded that Logitech is no longer really a pure China-tariff bet.
That is the kind of synthesis you actually want from work like this:
not just here are the assumptions
but here is what the company now is as a tariff debate
That is the difference between filling out a model and actually updating a thesis.
Case Study 2 – FDA Drug Approval
The second case study was a cleaner test of probability markets as an equity input.
Tariffs are messy. They involve policy, legal process, implementation, mitigation, and behavioural effects. Drug approval is different. It is narrower, more company-specific, and much more obviously resolvable.
So I gave the agent almost nothing to test it:
I want to use Polymarket to create a probability-weighted outcome model/scenarios for Eli Lilly
The obvious market was:
“FDA approves Retatrutide this year?”
At first glance, this is exactly the sort of thing an analyst should want: a live market-implied probability for a major pipeline catalyst at Eli Lilly (LLY).
And in fairness, this turned out to be one of the better use cases for probability markets.
But again, the good part was not that it found a market and used the price.
The good part was that it worked out how much of that price was actually useful for equity analysis.
The Output
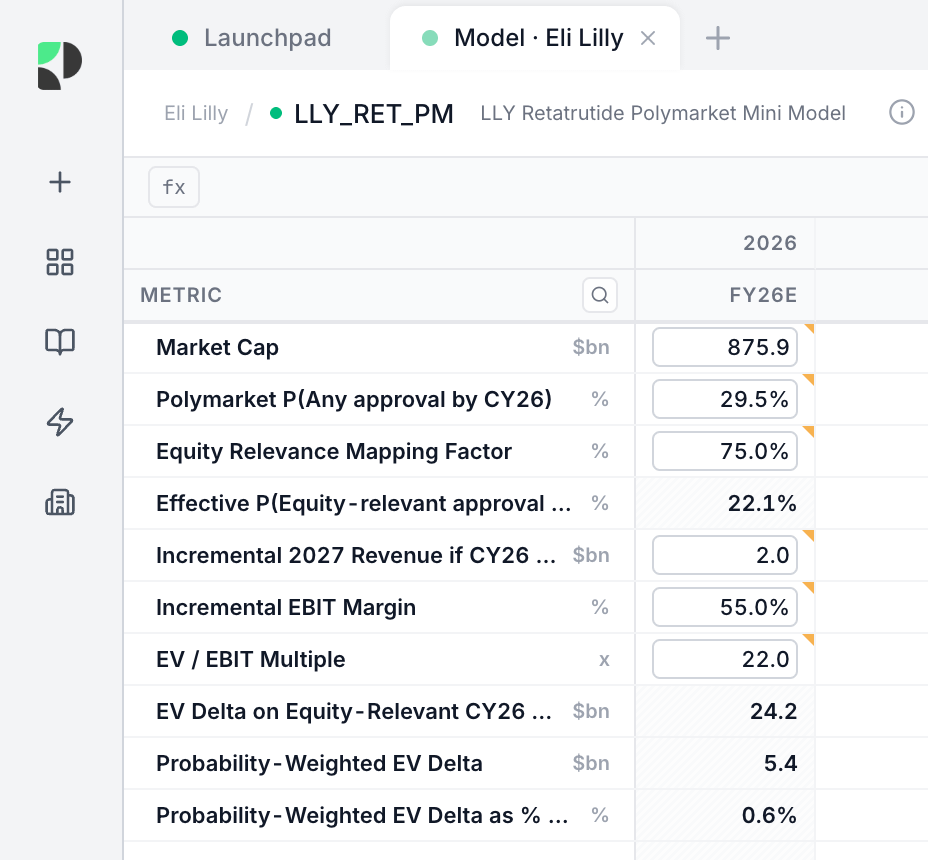
The model it built was intentionally small.
It started with the raw Polymarket probability, adjusted for how well the contract mapped to the actual equity question, and then estimated the value of bringing approval forward into 2026 rather than trying to use the market to value the entire retatrutide franchise.
The key outputs were:
Raw Polymarket approval probability: 29.5%
Effective equity-relevant probability: 22.1%
EV uplift on a genuinely equity-relevant 2026 approval: c.$24.2bn
Probability-weighted EV uplift: c.$5.4bn
As a percentage of Lilly’s market cap: 0.61%
That final figure was the important one.
The market was useful. But it was much less powerful than a quick glance at the contract might suggest.
What was actually good here
1) It chose a market that was actually worth testing
A lot of probability markets are too broad, too noisy, or too far removed from company fundamentals to be genuinely useful.
This one was different because it was:
tied to one company
tied to one named asset
tied to one clear regulatory event
objectively resolvable
That alone made it a much stronger equity test case than most macro or political markets.
2) It recognised that the contract and the equity question were not the same thing
This was the most important point.
A weaker model would have said:
Polymarket is 29.5%
therefore approval probability is 29.5%
therefore plug that into valuation
Instead, it noticed that the contract resolved on any FDA approval, for any use, by end-2026.
That is not quite the same as the question the stock cares about.
For equity holders, the important issue is not simply whether retatrutide gets some approval. It is whether the approval meaningfully de-risks the broader commercial opportunity in a way that matters for Lilly’s valuation.
Those are not identical things.
A narrower approval could resolve the market “Yes” without carrying the full economic meaning that the headline might imply. So the model applied a mapping haircut rather than using the raw probability mechanically.
That was exactly the right judgment.
3) It checked the market against company evidence
The output did not treat the market as an oracle.
It grounded the setup in Lilly’s own disclosures, which broadly pointed to:
retatrutide still being in broad Phase 3
key development milestones still in front of the company
launch timing framed more naturally around end-2027 than imminent 2026 approval
That matters.
The right hierarchy is still:
company evidence first
market-implied probability second
Probability markets can add information, but they should not be allowed to overwrite the underlying fundamental work.
4) It modelled the timing effect, not the full value of the drug
This was another strong choice.
The lazy version of the exercise would have tried to use one binary approval market to value the entire retatrutide franchise.
That would have been far too blunt.
Instead, the model asked the narrower and more sensible question:
what is the value of pulling approval into 2026, rather than getting approval later?
That is a much better use of the market.
Lilly already has a huge obesity platform. So the contract is not telling you whether there is a franchise at all. At best, it is telling you something about one timing node inside a much larger valuation problem.
Treating it as a timing input rather than a total valuation shortcut made the exercise much more credible.
5) It showed that useful does not mean decisive
This was probably the most honest conclusion in the piece.
The output did not overclaim. It did not pretend this was some massive edge. It showed that, even after using the market properly, the probability-weighted impact was only around 0.6% of market cap.
That is a very useful result.
Because in real research, the right answer is often not:
this changes everything
or this is irrelevant
It is:
this is real, but second-order.
That is exactly the sort of conclusion serious modelling should produce.
6) It made a clear recommendation
Again, it did not hide behind “it depends.”
The conclusion was straightforward:
use the retatrutide market as a narrow probability anchor
adjust it for contract wording and economic relevance
do not use it as a direct proxy for Lilly valuation
and do not build the stock thesis around it on its own
That is the right answer.
The broader takeaway
What these examples showed me is that probability markets are not a replacement for analyst work. They are not a shortcut around understanding the company. And they are definitely not something you should just plug into a model raw and call it sophisticated.
But they can be extremely useful when used properly.
The right workflow in my view is:
identify the relevant market
test whether the resolution wording actually maps to the company question
translate the raw probability into an economically relevant probability
weight the incremental impact, not the whole model
then make an opinionated judgment about how much of the market signal you really want to use
That is where AI becomes genuinely useful.
Not because it removes judgment, but because it can do the heavy lifting fast enough that judgment becomes easier to apply.
